
This tutorial shows how to use ProM 6 to answer some of the common questions that managers have about processes in organizations. First, the questions] are listed. To answer these questions, we use the process mining plug-ins supported in ProM 6. This tool is open-source and it can be downloaded for free. For the reader unfamiliar with process mining, second we provide a concise introduction. Third, all the questions listed are answered based on an event log from the running example.
We advice you to have ProM 6 at hand while reading this tutorial. This way you can play with the tool while reading the explanations. For this, please see the ProM 6 getting started page.
Common Questions
Questions that managers usually have about processes in organizations are:
- What is the average/minimum/maximum throughput time of cases?
- Which paths take too much time on average? How many cases follow these routings? What are the critical sub-paths for these paths?
- What is the average service time for each task?
- How much time was spent between any two tasks in the process model?
- How are the cases actually being executed?
- Are the rules indeed being obeyed?
- How many people are involved in a case?
- What is the communication structure and dependencies among people?
- How many transfers happen from one role to another role?
- Who are important people in the communication ow? (the most frequent flow)
- Who subcontract work to whom?
- Who work on the same tasks?
We show how to use ProM 6 to answer these questions in this tutorial.
Process Mining
Nowadays, most organizations use information systems to support the execution of their business processes [8]. Examples of information systems supporting operational processes are Work ow Management Systems (WMS) [5, 6], Customer Relationship Management (CRM) systems, Enterprise Resource Planning (ERP) systems and so on. These information systems may contain an explicit model of the processes (for instance, workflow systems like Sta ware [3], COSA [1], etc.), may support the tasks involved in the process without necessarily defining an explicit process model (for instance, ERP systems like SAP R/3 [2]), or may simply keep track (for auditing purposes) of the tasks that have been performed without providing any support for the actual execution of those tasks (for instance, custom-made information systems in hospitals). Either way, these information systems typically support logging capabilities that register what has been executed in the organization. These produced logs usually contain data about cases (i.e. process instances) that have been executed in the organization, the times at which the tasks were executed, the persons or systems that performed these tasks, and other kinds of data. These logs are the starting point for process mining, and are usually called event logs. For instance, consider the event log in the table below. This log contains information about four process instances (cases) of a process that handles fines.
| Case ID | Task Name | Event Type | Resource | Date | Time | Miscellaneous |
|---|---|---|---|---|---|---|
| 1 | File Fine | Completed | Anne | 20-07-2004 | 14:00:00 | … |
| 2 | File Fine | Completed | Anne | 20-07-2004 | 15:00:00 | … |
| 1 | Send Bill | Completed | system | 20-07-2004 | 15:05:00 | … |
| 2 | Send Bill | Completed | system | 20-07-2004 | 15:07:00 | … |
| 3 | File Fine | Completed | Anne | 21-07-2004 | 10:00:00 | … |
| 3 | Send Bill | Completed | system | 21-07-2004 | 14:00:00 | … |
| 4 | File Fine | Completed | Anne | 22-07-2004 | 11:00:00 | … |
| 4 | Send Bill | Completed | system | 22-07-2004 | 11:10:00 | … |
| 1 | Process Payment | Completed | system | 24-07-2004 | 15:05:00 | … |
| 1 | Close Case | Completed | system | 24-07-2004 | 15:06:00 | … |
| 2 | Send Reminder | Completed | Mary | 20-08-2004 | 10:00:00 | … |
| 3 | Send Reminder | Completed | John | 21-08-2004 | 10:00:00 | … |
| 2 | Process Payment | Completed | system | 22-08-2004 | 09:05:00 | … |
| 2 | Close case | Completed | system | 22-08-2004 | 09:06:00 | … |
| 4 | Send Reminder | Completed | John | 22-08-2004 | 15:10:00 | … |
| 4 | Send Reminder | Completed | Mary | 22-08-2004 | 17:10:00 | … |
| 4 | Process Payment | Completed | system | 29-08-2004 | 14:01:00 | … |
| 4 | Close Case | Completed | system | 29-08-2004 | 17:30:00 | … |
| 3 | Send Reminder | Completed | John | 21-09-2004 | 10:00:00 | … |
| 3 | Send Reminder | Completed | John | 21-10-2004 | 10:00:00 | … |
| 3 | Process Payment | Completed | system | 25-10-2004 | 14:00:00 | … |
| 3 | Close Case | Completed | system | 25-10-2004 | 14:01:00 | … |
Process mining targets the automatic discovery of information from an event log. This discovered information can be used to deploy new systems that support the execution of business processes or as a feedback tool that helps in auditing, analyzing and improving already enacted business processes. The main benefit of process mining techniques is that information is objectively compiled. In other words, process mining techniques are helpful because they gather information about what is actually happening according to an event log of a organization, and not what people think that is happening in this organization.
The type of data in an event log determines which perspectives of process mining can be discovered. If (i) the log provides the tasks that are executed in the process and (ii) it is possible to infer their order of execution and link these tasks to individual cases (or process instances), then the controlflow perspective can be mined. The log in the table above has this data (cf. fields “Case ID”, “Task Name”, “Date”, and “Time”). So, for this log, mining algorithms could discover the process in the figure below (The reader unfamiliar with Petri nets is referred to [7, 9, 10]). Basically, the process describes that after a fine is entered in the system, the bill is sent to the driver. If the driver does not pay the bill within one month, a reminder is sent. When the bill is paid, the case is archived.

If the log provides information about the persons/systems that executed the tasks, the organizational perspective can be discovered. The organizational perspective discovers information like the social network in a process, based on transfer of work, or allocation rules linked to organizational entities like roles and units. For instance, the log in the table above shows that “Anne” transfers work to both “Mary” (case 2) and “John” (cases 3 and 4), and “John” sometimes transfers work to “Mary” (case 4). Besides, by inspecting the log, the mining algorithm could discover that “Mary” never has to send a reminder more than once, while “John” does not seem to perform as good. The managers could talk to “Mary” and check if she has another approach to send reminders that “John” could benefit from.
This can help in making good practices a common knowledge in the organization. If the log contains more details about the tasks, like the values of data fields that the execution of a task modifies, the case perspective (i.e. the perspective linking data to cases) can be discovered. So, for instance, a forecast for executing cases can be made based on already completed cases, exceptional situations can be discovered etc. In our particular example, logging information about the profiles of drivers (like age, gender, car etc.) could help in assessing the probability that they would pay their fines on time. Moreover, logging information about the places where the fines were applied could help in improving the traffic measures in these places.
From this explanation, the reader may have already noticed that the control-flow perspective relates to the “How?” question, the organizational perspective to the “Who?” question, and the case perspective to the “What?” question. All these three perspectives are complementary and relevant for process mining, and can be answered by using ProM 6.
ProM 6 [4, 11] is an open-source tool specially tailored to support the development of process mining plug-ins. This tool contains a wide variety of plug-ins. Some of them go beyond process mining (like doing process verification, converting between different modelling notations etc). However, since in this tutorial our focus is to show how to use ProM 6 plug-ins to answer common questions about processes in companies, we focus on the plug-ins that use as input (i) an event log only or (ii) an event log and a process model. The figure below illustrates how these plug-ins can be categorized.
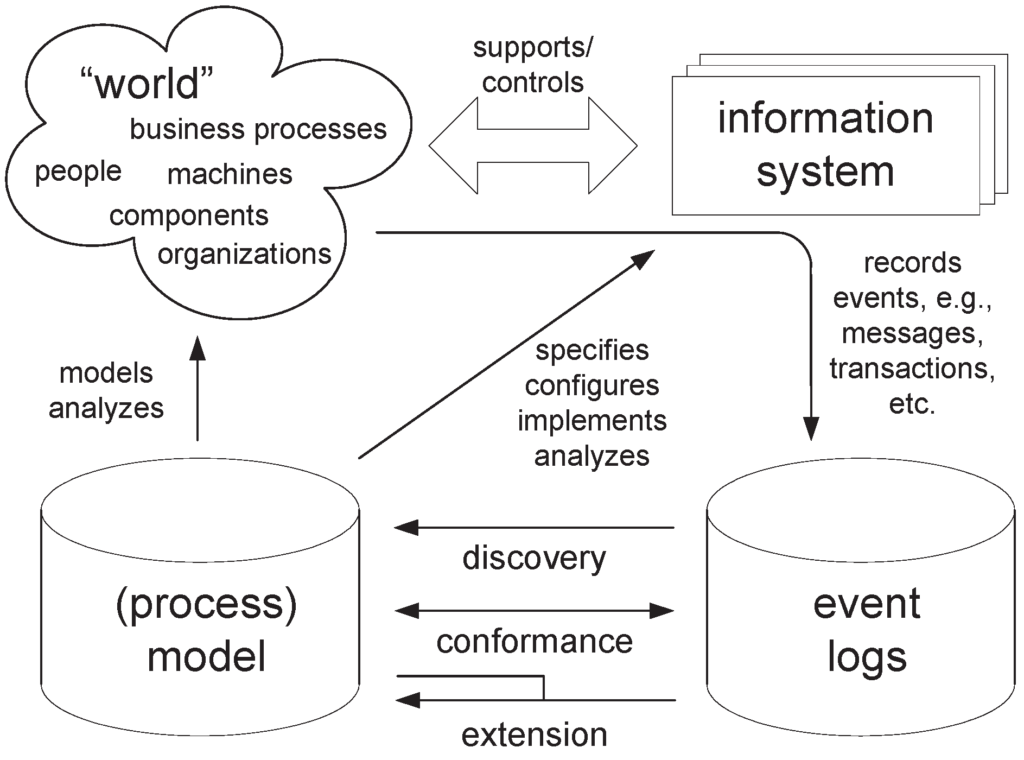
Discovery
The plug-ins based on data in the event log only are called discovery plug-ins because they do not use any existing information about deployed models.
Conformance
The plug-ins that check how much the data in the event log matches the prescribed behavior in the deployed models are called conformance plug-ins.
Extension
Finally, the plug-ins that need both a model and its logs to discover information that will enhance this model are called extension plug-ins.
In the context of our common questions, we use
- discovery plug-ins to answer questions like
- How are the cases actually being executed?
- Are the rules indeed being obeyed?,
- conformance plug-ins to questions like
- How compliant are the cases (i.e. process instances) with the deployed process models?
- Where are the problems?
- How frequent is the (non-)compliance?, and
- extension plug-ins to questions like
- What are the business rules in the process model?
Running Example
The running example is about a process to repair telephones in a company. The company can fix 3 different types of phones (“T1”, “T2” and “T3”). The process starts by registering a telephone device sent by a customer. After registration, the telephone is sent to the Problem Detection (PD) department. There it is analyzed and its defect is categorized. In total, there are 10 different categories of defects that the phones fixed by this company can have. Once the problem is identified, the telephone is sent to the Repair department and a letter is sent to the customer to inform him/her about the problem. The Repair (R) department has two teams. One of the teams can fix simple defects and the other team can repair complex defects. However, some of the defect categories can be repaired by both teams. Once a repair employee finishes working on a phone, this device is sent to the Quality Assurance (QA) department. There it is analyzed by an employee to check if the defect was indeed fixed or not. If the defect is not repaired, the telephone is again sent to the Repair department. If the telephone is indeed repaired, the case is archived and the telephone is sent to the customer. To save on throughput time, the company only tries to fix a defect a limited number of times. If the defect is not fixed, the case is archived anyway and a brand new device is sent to the customer.
The files required for the running example are contained in the example log files.